Know-How
This section will provide you with all the necessary information to understand and complete the Module 4 - Advanced AI section which revolves around creating AI models and making use of them in the logics builder. You will learn how to make regressions and classifications using only LOGIBLOX tools.
Guide on AI
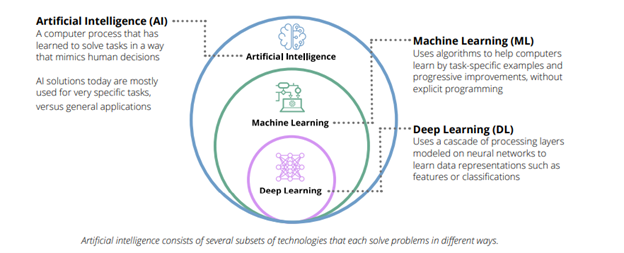
Artificial intelligence
AI is typically defined as the ability of a machine to perform cognitive functions we associate with human minds, such as perceiving, reasoning, learning, interacting with the environment, problem solving, and even exercising creativity. Examples of technologies that enable AI to solve business problems are robotics and autonomous vehicles, computer vision, language, virtual agents, and machine learning.
AI learning
There is one crucial thing you will need to bear in mind when it comes to Artificial Intelligence: It needs to “learn” before it can do something—anything—for your organization. This is true for both narrow AI, which can perform one specific task very well, and, most especially, general AI, which can do a variety of tasks such as language comprehension, problem-solving and object recognition.
Relation to human intelligence
To understand this dynamic better, consider actual human intelligence, which needs to learn how to do a task first before it can accomplish it correctly and repeatedly. And for learning to take place, there has to be some form of teaching, in which the specifics of the task are explained in detail—from background information about it to how the task is supposed to be done.
The same process enables AI to be “intelligent,” and it is made possible by machine-learning and Deep Learning. The former takes in various data-rich algorithms to learn how to process information based on all available data; the latter, on the other hand, builds on machine-learning by cascading what it has learned into different layers to enable abstraction, as when AI, for example, adds information to a given category.

In keeping with the human intellect analogy, it should be pointed out that context—prior knowledge and experiences, dynamic transactions with other humans and the environment and internalization of cultures and societal norms—is central to human learning.
The reason being is that context determines how people discern the important from the unimportant, in turn leading them to make decisions using information relevant to a given situation.
The same is true for AI, which also needs context in order to be human like in terms of making decisions—that is, based on information, depending on the situation and for the best outcomes possible, or at least the right ones. In fact, AI needs far more context to learn so it can better approximate the decision-making process of humans.
Machine learning
Machine learning is a branch of artificial intelligence and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.
Over the last couple of decades, the technological advances in storage and processing power have enabled some innovative products based on machine learning, such as Netflix’s recommendation engine and self-driving cars.
Why Machine Learning
Machine learning is an important component of the growing field of data science. Through the use of statistical methods, algorithms are trained to make classifications or predictions, and to uncover key insights in data mining projects. These insights subsequently drive decision making within applications and businesses, ideally impacting key growth metrics.
As big data continues to expand and grow, the market demand for data scientists will increase. They will be required to help identify the most relevant business questions and the data to answer them.
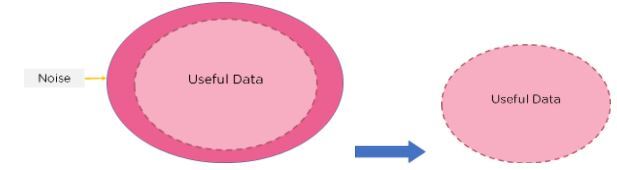
Feature Selection
Feature Selection is the method of reducing the input variable to your model by using only relevant data and getting rid of noise in data. It is the process of automatically choosing relevant features for your machine learning model based on the type of problem you are trying to solve.
We do this by including or excluding important features without changing them. It helps in cutting down the noise in our data and reducing the size of our input data.
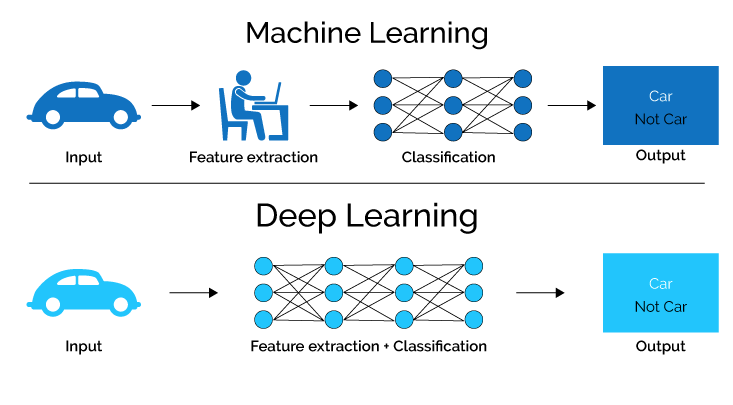
Deep learning
Deep learning is a type of machine learning that can process a wider range of data resources, requires less data preprocessing by humans, and can often produce more accurate results than traditional machine-learning approaches (although it requires a larger amount of data to do so).
In deep learning, interconnected layers of software-based calculators known as “neurons” form a neural network. The network can ingest vast amounts of input data and process them through multiple layers that learn increasingly complex features of the data at each layer.
The network can then make a determination about the data, learn if its determination is correct, and use what it has learned to make determinations about new data. For example, once it learns what an object looks like, it can recognize the object in a new image.
Time Series Predictions
Time-series is a type of data that is sampled based on a time-based dimension like days, months, years, etc. We term this data as “dynamic” as we’ve indexed it based on a DateTime attribute. This gives data an implicit order. Don’t get me wrong, static data can still have an attribute that’s a DateTime value but the data will not be sampled or indexed based on that attribute.
When we apply machine learning algorithms on time-series data and want to make predictions for the future DateTime values, for e.g. predicting total sales for February given data for the previous 5 years, or predicting the weather for a certain day given weather data of several years. These predictions on time-series data are called forecasting. This contrasts with what we deal with when working on static data.
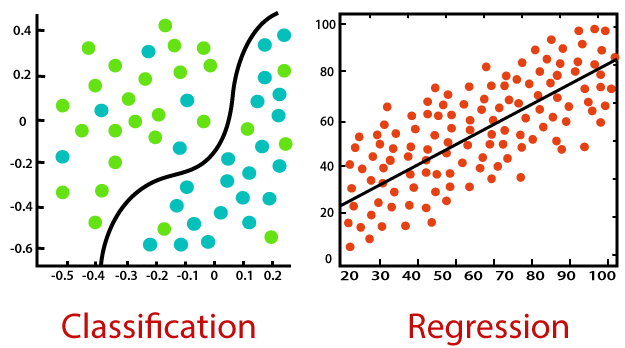
Classification
Classification is the process of predicting the class of given data points. Classes are sometimes called as targets/ labels or categories. Classification predictive modeling is the task of approximating a mapping function (f) from input variables (X) to discrete output variables (y).
For example, spam detection in email service providers can be identified as a classification problem. This is s binary classification since there are only 2 classes as spam and not spam. A classifier utilizes some training data to understand how given input variables relate to the class. In this case, known spam and non-spam emails have to be used as the training data. When the classifier is trained accurately, it can be used to detect an unknown email.
Classification belongs to the category of supervised learning where the targets also provided with the input data. There are many applications in classification in many domains such as in credit approval, medical diagnosis, target marketing etc.
Sources:
- An Executive's Guide to AI - McKinsey
- Knowledge Graphs: Providing Better Context and Deeper Insights - Data Storage ASEAN
- Taking Shape: Artificial Intelligence Regulation and Its Impact - Kvalito
Now its time to move on to the first mission of this section!